
To create something new, you need to make some noise.
- Ethan Smith
- Feb 1
- 27 min read
Updated: Mar 22

One of the most interesting things about the development of AI was the order of achieved milestones. Relatively small models can create convincingly masterful lifelike art while a much larger language model may fail common sense problems that your average 10 year old may have no problem with. But then at the same time, they are incredibly capable. The same language models failing at some trivial tasks may also explain difficult math concepts in a very intuitive manner and write genuinely interesting prose. How do we reconcile with this?
Does it say something fundamental about the difficulty of things? Is it a matter of the medium and modeling techniques applied? For instance the diffusion model gets to de-jitter pixels until a work of art is revealed while the human is bottlenecked to local view of a canvas and must create it stroke by stroke. Is it a matter of what our criteria of success is?
My personal view is it's a mix of all of the above.
There may be a more objective universal difficulty metric for creating an output that may not always be correlated with what humans find difficult. The ways humans have adapted has put a priority on ensuring the tasks we are good at are the ones that are most integral to survival and everyday functioning, whatever is most evolutionary favorable. If there was somehow an intelligent creature on this earth whose evolutionary fitness metric for many millenia was rated by the quality and/or quantity of art it created- its lifeline and shot of preserving its bloodline into the future depending on it, who knows in what kinds of ways it would adapt and what it may consider easy versus challenging?
Another avenue for human bias is the ways in which we rate success or our threshold for being impressed. For instance, something like art or poetry has many "correct" answers, and the right dosage of spontaneity is a quality often rewarded. Meanwhile, a math problem generally has one correct answer that must be reached, and the reasoning along with the work shown may only have a few acceptable paths. Thus there are fewer trajectories with strict criteria that must be met for us to be convinced.
Recalling for a moment that popular generative models like diffusion models or autoregressive transformers effectively funnel random samplings into desirable information and trajectories, it would seem that the number of desirable trajectories relative to all that could be outputted at least partially explains what makes a task difficult. Going through 100s of matrix multiplies with each forward pass and placing all the tokens necessary in order to fall upon a few correct trajectories feels like trying to reach the last pin in bowling, but throwing from the moon (while the way probability weighs outcomes very much constrains this, its still pretty nebulous! Just mentioning this before I get hit with "but so do humans!") . This perhaps gives a reason for part of the benefits around chain-of-thought, self-reflection, and other prompting methods. By offering scaffolding, signal from external verifiers, and the ability to extend rollouts further by correcting itself and backtracking, we can help avoid veering off track as well as opening the door to more paths that can reach an answer.
While it might be frustrating that the difference between a correct answer and an incorrect one could be a matter of RNG noise, or random samplings, it's an incredibly interesting part of the generative process. In this post, I want to talk about how in the right doses, with the right guidance or filtering, and with the right luck, noise generates novelty. Novelty right at the fine line between collapse into incomprehensibility and striking gold on an uncharted frontier.
Noise for exploration
It's well known that noise can be used to more extensively search a space and balance exploration vs exploitation tradeoffs. To make this more concrete, we'll go through an example.
Let's imagine we have a space of all the wolves in the world. Every point in this space represents a wolf with some different genetic makeup responsible for its attributes and phenotypes.

We can imagine though our x-axis corresponds to something like amount of fur and y-axis to fur color. Then just imagine there are many, many other dimensions we can't visualize representing similar ideas.
As wolves breed, they create new wolves, which arise as a point on a line somewhere in between the two parents.
With these rules in place, our job now is to somehow obtain dogs from steps of cross-breeding.
To start, we'll imagine that genetic mutations are not present here. There is no randomness. Crosses here will be represented as linear interpolations in space, the main tool at our disposal. We'll assume there are no "invalid" crosses, all result in viable offspring. Normally, these would be regions of space blocked out, a no-mans land. We'll also remove gender from the equation, we can perform crosses between any two points.
If this is the case, we are actually fully confined to a limited search space defined by the biggest outliers in each direction. Let's run some crosses to see what we mean by this.

The blue points represent our next generation. Each sits somewhere on the line between the two parents, randomly deciding how far along that line. We'll run one more generation, choosing points at random and mixing them.

Notice that we can't leave the convex polygon defined by the original red points, vastly confining the extent of what we can search. All the new points with each generation are a predetermined kind of "new". They are all novel and unique in that they haven't previously existed, but obscured behind a fog of war that we have a clear path to. But we still can't reach uncharted regions. Enter noise.
Some form of randomness is generally an essential part running an evolutionary optimization algorithm, with the main questions being around what the right dosage is for having good coverage of a space while still being able to zero-in on a solution once we've found one. Not too dissimilar from how different real life species have different mutation rates, and how mutations can be become as much an obstacle resulting in unviable offspring as a benefit helping increase overall evolutionary fitness. (side note: see Hinton's wonderful theory on dropout in neural networks and a possible evolutionary analogue in reducing reliance on highly co-dependent genes in the motivation section)
Let's start again from the beginning, but this time after each linear interpolation we randomly jitter where the point ends up.

See now that we've broken free from our enclosure! Now its much more reasonable to imagine after many generations of crosses, and the right selection of what bloodlines continue, we could end up with dogs.
In this example, we might say that the interpolations give us "trivial novelty" while the noise gives us proper, more unexpected novelty.
A common accusation towards AI models is that they do not actually innovate, they "just interpolate" their training data. Under our discussion, meaning they are only capable of trivial novelty. I'm not 100% on the accuracy of this statement, or at the very least, uncertain if this is the right perspective.
For methods like Kernel regression, the entirety of what they do is to quite literally interpolate data points. I believe a similar case may also be made for deep learning classifiers. Their input space can be any possible value, but each is mapped to a single deterministic output value. It is not guaranteed that the learned model can have coverage of the entirety of the output space (-inf, inf), and in fact, that's usually not the case.

For something like generative models like diffusion and Large Language Models, I believe this reductionist view is still valid, (this paper describes how diffusion models interpolate data). Though we now have the added complication of sampling noise contributing to an output as well, making the final result not a just mixture of data points but a blurry field around a given mixture. Perhaps something like this for our evolution example:

Where this gets a little fuzzy for this probablistic approach to generation, is that this noise allows for all possible output data points are under support, meaning everything can occur with non-zero probability. It theoretically could create any possible image, any possible text, and so on. Though the probability of doing so might be infinitesimally small. Inversion methods show us that for any image, we can discover a noise that approximately produces that image, though it is well known that these noises can sometimes be very rare with respect to the standard gaussian.
So even if the main tool at our disposal is only interpolations, when we also wield noise, we have the potential for access to the entirety of the output space, not too dissimilar from our evolution example.
This throws a bit of a wrench in the "just interpolations" perspective and the belief that AI cannot achieve novelty. Even if it is just interpolations, if everything that could ever possibly exist could be generated, and AI is incapable of producing novelty, then we would have to conclude that nothing is, or ever will be novel!
When we generate sequences of text with a language model, there's two forms of generation: stochastic sampling and argmax sampling.
At every step of generation the language model does not predict the next word but instead presents a list of probabilities of every word in its vocabulary being the next word (technically token). Argmax sampling will choose the highest probability word at every single step, yielding a single deterministic trajectory. Any form of stochastic sampling will randomly choose a word from its vocabulary, weighted by the predicted probabilities. Under stochastic sampling, any sequence of text could occur generally with non-zero probability, though it may be exceptionally rare.

In this case, "The dress color was lymphoma" is a possible arrangement of words, though a very rare and unexpected outcome.
Even rarer, might be completing "The dress color was _____" not with a single next word but instead a description of your entire life story, from everything that has already happened to everything that will happen. Profoundly rare, but not impossible. This is the principle behind the Library of Babel, a thought experiment of an infinitely large library, containing every possible text that could exist.
Nowadays, many sampling techniques with LLMs utilize stochastic sampling. If we presented the LLM with a math problem and hoped to solve it with argmax sampling, we have only one shot at getting it right as there is only a single deterministic string we produce. Instead, we could imagine running stochastic sampling 100 times, and trying strategies like Majority Voting (what is the answer that the majority of generations give?) or if we have a means of rating generations by their results or thought process, we could prioritize those with promising reasoning while pruning out those that have screwed up early on.
Another trick one can do is adjust the temperature of the distribution. Effectively, decreasing temperature rescales the distribution such that higher probabilities surge higher while lower probabilities drop even lower, thus "sharpening" the distribution. Raising temperature on the other hand will give you back a uniform distribution in the limit where every word has equal probability.
You can see as well in the diagram below that using lower and lower temperatures will eventually place the entirety of the probability mass on a single word, bringing us right back to argmax sampling.
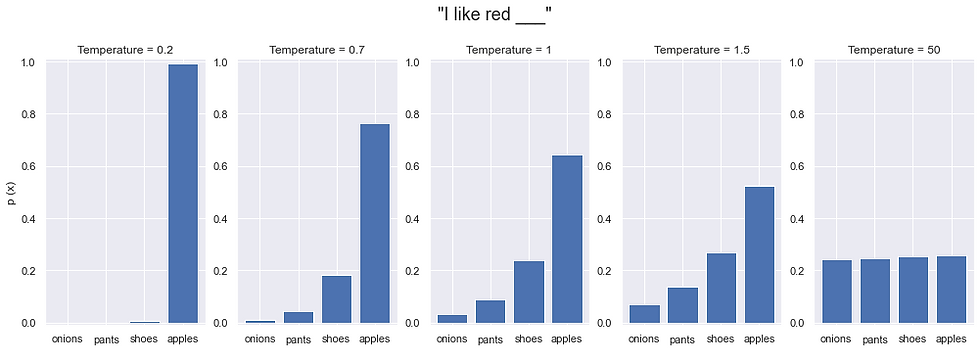
One interesting observation is many users have cited that higher temperature sampling can yield more diverse and interesting outputs. This is not a coincidence. Diversity of output lies in the definition. We upweight the probability of less likely outputs. Following, you're bound to explore rarer regions of the space of text, similar to the point made with our "The dress color was lymphoma" example.
However, the connection to how interesting outputs are could use some elaboration. Rarer outputs are said to be of higher entropy, which is sometimes called surprisal. This should make sense, Lymphoma is a surprising way to describe a dress color. On the other hand, lower temperature sampling might lead to extremely predictable, possibly cliche, sounding text. In the right doses, this "off the beaten path" style of sampling should allow for us to encounter novel pieces of text. You increase the risk of nonsensical text, but some generations might wield unexpected and clever prose, hence its interestingness.

From this, my read is that novelty is born from the far-fetched moonshot attempts of traversing uncharted areas of data space, but the subset of those that happened to still make enough sense to have meaning to still captivate human attention.
This is a subjective evaluation, meaning the criteria of interestingness and making sense, and what we consider "order", is specific to the human experience. We can achieve maximum surprisal by just entirely randomly picking words out of a hat like the following:
preship malproportion angelology anarchical bonnyvis
dowless embossman oryctics protonymphal amorpha
piratize determinate spyboat roentgenograph snod
peritrichan magnetoid dressline mocuck preprofess
Though ironically, despite these being the most surprising outputs we can create giving the greatest potential for novelty, they all look almost equivalently nonsensical!
Similarly, here is 4 images of randomly sampled RGB color values, aka noise.

Again, they are all extremely different from each other, but not in any way that is meaningful to us. For both the text and images, I notice my mind blanks out at what I'm looking at in the same kind of way.
Now something that may have been novel and interesting is the pioneering works of the Impasto painting style by Van Gogh, which deviated from typical art styles at the time.

Compared to what other kinds of art were prevalent at the time, this may have been properly surprising. Since his fame and widespread iconography of his work, it is probably less surprising, which reflects the fact that surprisal or the amount of "information" something conveys is relative to its context or distribution. In another universe, this could have been the norm, and photorealistic-style paintings were what shocked the world. This fact took me a long time to really understand deeply, that any given data point in isolation is meaningless, perhaps as meaningless as the random noises sampled above, and that meaning is with respect to a context. Context being all the surrounding factors that describe the point, like how rare it is in a given scenario, or how it compares to other points. This is particularly visible with value. On earth, diamonds are an expensive rare jewel. On 55 Cancri E, finding a diamond would be one of the most lackluster, ordinary things that could happen. Or another example is we can imagine a world where everyone had the same name. This would defeat the whole identifying utility of names and destroy the information they convey as well. It is variance in an attribute that allows things to have meaning.
To illustrate this more concretely, a work in machine learning image classification showed that the features that image classifiers latch onto may not always correlate with human perception, and what appears random to us may be deeply meaningful to machine learning models! It just goes to show how highly specific our perceptual preferences, our language, and our visual grammar are in the space of all possible understandings. One question that arises from this is, what is the minimum amount of order needed for us to insert meaning? The way we see shapes in clouds suggests this could actually be quite little, though this is likely not a hard threshold and varies person to person.
For a similar reason, I have appreciated the AI generated imagery of smaller and older models. They hopelessly misfired at a faithful model of the distribution of images, though enough sense was often conveyed for it to be interesting.

I have often considered myself a "novelty junkie." I get bored quickly and am always looking for new sources of excitement. Though I think this is true of humans more generally, at least up to some degree.
At the most fundamental level, our brains are always gravitating towards homeostasis. Simple optical and auditory illusions reveal how apparent stimuli can fade out of our perception with given time once our brain decides to ignore it and not expend any further processing power. We are always adjusting our sensitivity, down-weighting it for things as they become more and more typical and ordinary.
This has more familiar implications as well. How many times can a joke be heard before its no longer funny? How many times can a movie be watched or a song heard before its no longer moving?
I notice that technology has accelerated this process. Meaning derived from rarity of occurrence is dwindling. Through VR, phones, planes, and beyond, rich and diverse experiences have never been more accessible and on-demand, even if a bit inorganic at times. A friend of mine has described this age as "Content Infinitum" where content is created quite literally faster than it can be consumed, though it might not be able to keep up with our increasingly extreme standards.
Look across each generation's examples of humor. Memes have become increasingly esoteric, having fallen and rebirthed through several cycles of irony by now, just to scratch the itch of discovering absurdity that truly catches you off guard. My own generation went from bad luck brian memes to this kind of thing by just 2016 or so:

Timelines are accelerating...
The question I have now is, is noise a fundamental component for creating novelty? Noise being the sporadic, unpredictable, and sometimes unstable nature of humans, allowing for extensive exploration.
In another post, I tried to break down what randomness even is, and concluded much of what we call noise is actually meaningful processes that lie beyond our modeling capabilities, which for scientific purposes, it has sufficed to describe it as noise.
So possibly we shouldn't write this off as noise, but instead look at is as a deliberate seeking of novelty for the self, and in doing so, strays away from the rest of the crowd.
Funnily enough, a recent paper describing "creativity" in diffusion generative image models mentions that it is the imprecision and inaccuracy of the learning, which we can think of as an underfit or noisy approximation, that allows for "combinatoric creativity", otherwise they would collapse into memorization. There is only one way to memorize something 1:1, while there is a nearing infinitely many ways to miss a point and generate perturbed versions of data, like an arrow hitting a target on the bullseye versus anywhere else on the board. From the paper:
"The fundamental creativity of diffusion models must lie in their failure to achieve the very objective they are trained on"
There is a lot more here that can be said about when hopfield networks fail to retrieve a data point and instead give you an interpolation of two points, and how diffusion models, like a modernized version of the Hopfield network, can successfully recover plausible "in-betweens". Or how the difference between human hippocampus memory retrieval, often modeled by hopfield networks, and imagining something new is less than one might think, with a similar distinction to recovering a previously seen point or "landing nearby" others.
In thinking about the human drive to seek out novelty balanced with the criteria that things must still make sense to us, I attempted to create a generative model that is judged by both of these called NoveltyGAN. The GAN objective asks that generated images be perceptually convincing, but then the trick is we use a pretrained density model (Diffusion, autoregressive, normalizing flow, VAE ...) and flip the sign of the loss, which asks for the images to be of lower probability with respect to its context, prompting exploration of rarer regions of space. I had very limited play with it, and my gut tells me using diffusion for the density estimate might not be as great as something like a normalizing flow, which has recently showed the capability to make for expressive generative models on diverse datasets. A possible pitfall is that the model can create adversarial outputs that are not conventionally perceptually-convincing but still enough in a way to trick the discriminator, satisfying both constraints but never reaching images that are inteligible to us. Though as an area of study, I think understanding how we can balance novelty-seeking while maintaining a faithful model of the world is very interesting.
Granted, there's likely more convenient ways to explore low-density areas, like conditioning for instance. A rare piece of text may lend itself to a relatively rare image. We can visualize this with a 2D gaussian, where we are allowed to fix one of the coordinates. When we do this, we slice out a 1D gaussian to sample, which can be in a lower space of probability in the global space. So one method of attack could be instead of training novelty-seeking directly into the model, instead training a secondary component to identify conditions that select or query for rarer regions of space. If the query or condition is rarer, so should the output. And this is part of why I'd argue novelty lies in creative search and sampling.

We could even imagine using the density estimates from a pretrained model to condition another generative model, letting us select for how "rare" of an output we'd like at inference time.
A more practical example is using text to query images. If we make our texts much more verbose and detailed, we also target finer narrower regions of space.
As an example, picture in your head "a cat". Not a ton to go off of. You probably imagined a fairly conventional cat, though there was nothing specifying what breed of cat, its size, its location, or anything else.
"A kitten" is a bit more informative, we now know its age. "A white kitten sitting in the grass" now fills in much more of what was left as open interpretation.
Finally, "A white 1-month old kitten wearing a top hat and monocle is sitting on a lawn chair on a sunny day while reading a Times magazine titled 'Cats of The Year'" is now not only adding a substantial amount of detail but also specifying a pretty rare occurrence. The space of images that meets this criteria is substantially smaller. And one step beyond, many pipelines these days use "prompt upsampling" where a piece of text is ran through a language model to be made far more detailed. The end result is this.

Predetermined Novelty
Pivoting back to the previously mentioned point on predetermined novelty, I wanted to discuss the search processes that go into things like art and research, both things I have have had some experience with firsthand.
Art and research can both be considered as a searching over a space or an optimization algorithm. Ultimately, we want to reach an output that has value, whether that be academic merit, advancing new technologies, an observation that one's painting skills have improved, or aesthetics or expression appealing to self or others. Let's also not forget the value and enjoyment of the journey itself, especially for art, though that's a different topic.
I would argue that art, for a number of reasons, has a much more ambiguous search space and noisier search process. For one, the landscape of value one consults when making art varies substantially person to person. We could assess the aggregate sense of value held by the masses, and this is typically what reward regression models learn assuming they've been trained on a properly diverse bag of ratings by many people. Though regardless, its likely that our own individual, subjective senses of value still inform the process. Secondly, as mentioned earlier, there are many "correct" answers, and its not always obvious what that is. The criteria for "good art" is qualitatively ambiguous. In the face of that uncertainty, our limited perspective and biases, and how our own desires drive the process, I would argue we are less driven towards a universally agreed-upon ideal and instead prompted to explore quite sporadically.
On the other hand, research can be made very rigorous. Research typically involves firm quantifiable and objective criteria, making use of prior work to predict future outcomes, and a strict process to ensure reproducibility. Whereas art welcomes all kinds of approaches, research generally asks that all follow a set of rules to participate in the conversation and deliver robust findings. "Make a nice piece of art" is a far less constrained objective than "Make the language model faster", and depending on the kind of person you are, whether you love the expanse of creative freedom or need narrower well-defined structure in your endeavors, either objective may be more frightening.
To emphasize though, this is my read of the conventional cases for these lines of work. Art could be made into a stricter optimization process trying to reward-hack what brings in revenue, and some independent researchers, especially in open-source, may come up with their own processes leading to novelty and value in their own right. I think there is somewhat of a spectrum describing the strictness, noisiness, and breadth of the search/optimization processes with regards to how many minima ("correct answers") there are, how scattered apart these minima are, and the clarity and objectivity of the goal.
In my experience, research in AI often feels like there is a looming hand of fate guiding its direction. There are some cases the writing is practically on the wall as to what the next step in development is, and this can often lead to several concurrent works exploring the same technique. Somehow, and I say this naively, many of our milestones feel like they were destined to happen, and rather its just a question of when. For instance, I wonder across how many universes, starting from the date deep learning first erupted on GPUs circa the Imagenet competition days, transformers became the dominant network run on GPU hardware, or where where the paradigm of self-supervised pre-training followed by reinforcement learning arose, or convolutional networks had a period of fame. It feels like fate because it feels like there is an already existing set or rules written into the universe dictating what works and what doesn't, and in pushing along different fronts and discovering what continues to advance and what hits a dead end, we naturally follow some kind of predetermined river flowing us towards desirable outcomes, though perhaps not in a required order.

This very simplified view won't reveal how methods may go dark and later resurface or how the river may split and recombine but I think it gives a rough idea of the process. This river isn't something we can see, though its there, shaping and filtering our work, not so different from feeling your way through the dark and using the walls to guide your path. I would describe the progress of research to resemble most closely to something like Particle Swarm Optimization, in that we have parallel ongoing searches in different regions, the deepest minima attracts the most attention and hands, though we have the means for a good bit of coverage over less obvious regions as well.

In due time, with lots of mistakes and some breakthroughs, we are coaxed to glide down the slopes of optimization towards what our universe (and current hardware) allows to be performant. Roughly, I like to imagine it as each era of research is spending time converging to a minima, seeing how deep that minima truly is, and then by chance discovering a new frontier suggesting there are even deeper minima out there with an illuminated path towards them.

That red line illustrating the breakthrough, but initially having worse results than current methods is what keeps me up at night. Quite a few times, a new method is produced and it is clear that this will change the game. Other times it may not be so clear. It makes me wonder how much has been shelved because it lacked the hardware for it to be practical at the time, or maybe never got the right attention for lots of minds to tinker with and see the future paths? If you weren't around for it, try to imagine what it would have been like to see the first works on transformers or diffusion models, and whether the strength it has today would have appeared predictable. What is happening right now that could amount to having a similar caliber of legacy if anything?
Predetermined novelty is less obvious with art. There are far less rules. We could make a few educated guesses, like that the photorealism style was perhaps bound to arise. It feels like it aligns with human's imitative nature and offers a contest of who can paint a reference most faithfully, catering to our competitiveness. Science-fiction kinds of art feels also pretty likely, that a fascination for progress and extrapolation into the future may inspire how we create. Though guesses here feel a bit handwavey and harder to formalize.
Strangely though, my experience with making art has felt closer to my description of research in some ways. I never picked up an aptitude for painting or other means of creating art. Though at the start of high school, I had discovered the remove background tool for images in Microsoft Word along with the formatting that allowed you to overlay multiple images together to make collages, which was a common passtime during unexciting classes. Though the degree of freedom was fairly limited. Soon after, I had received a license to photoshop which my school offered. The photoshop interface felt like an airplane cockpit with its overwhelming amount of controls, though driven by curiosity, I had to try all of them.
To me, this was a very different experience for creating art. I didn't need to have the dexterity to maneuver a brush, Ctrl+Z offered infinite forgiveness, and the layering/visibility switches allowed me to maintain multiple versions of an ongoing piece.
The overall process was pretty ritualistic. I'd grab a few images that seemed like they could have some potential, though generally did not have a clear vision in mind. Then I'd start running down my list of go-to strategies for adding flair or general interestingness to the canvas. I would then visually assess those that were worth continuing with and those that did not fit, often making several checkpoint copies, so I could recover if a direction I took did not work out. From there, it was rinse and repeat, gradually moving outward from my typical methods to simply brute-force trying every single offered tool.
I ironically found this process stressful. To begin with, the space of all next steps to take was huge, and the possibilities for compositions of multiple steps grew combinatorically. Though I had to try as many directions as I could for fear that I would overlook a promising path. Secondly, my evaluation criteria was fickle. Towards the end of a piece, I would fiddle around with fine adjustments to the color sliders, sometimes at what I think was an imperceptible level, for up to days on end. I would switch between versions back and forth obsessively while having no read on which was actually better.
This style of search over a set of paths made it feel less like I was creating and more that the end result already existed in a predetermined way. In other words, it was almost that I was pulled towards this result through a similar means to the research description, via iterative improvement and filtering out dead ends. All of this decided by my evaluation criteria and policy for chosen actions, which, while this is always in flux and may vary moment to moment, I realized I was predictable enough to have a general sense of where things would go and feel the sense of inevitability.
I can't speak to the experience of creating art outside of my own experience, and while iteration is a big component of any kind of creative work, I do picture it as generally being less annoyingly structured than I have made it out to be.
This spectrum of free-flowing exploration and constrained optimization has made me think a lot about the industrialization of art and the "Marvelification" of media. Marvelification, the namesake taken from Marvel, a prime perpetrator, is a term I've used to describe the dwindling creative ambition in film, leading to excessive clichés, hollow characters, and high spend on flashy CGI eye candy to hide away that the film was not built from expression but instead a cash-grab formula. This is obviously not the case for all media, though you may have felt this with the particularly big names.
It makes sense. The budget that goes into films is massive. Investors want to have faith that they will see a positive return. Identifying the key factors that have historically worked to drive box office and exploiting them, from an economic perspective, I would say is pretty wise. Though as a viewer, you can smell it, it's palpable. It is clear which age demographic each inserted joke is meant to appeal to, how a film is engineered to bring out as many kinds of audiences as possible, and how it's already been planned out in advance how to turn the characters into McDonald's happy meal toys. Sequels, despite the poor reputation for often falling short when compared to the original, have the benefit of higher odds of bringing back the same crowd from the first success. This is why we're now on Ice Age 6, Toy Story 5, and Shrek 5 upcoming in 2026. Or why book-adaptations are so common even if fans often feel the film doesn't do the book justice. You can exploit a preexisting fanbase that will inevitably see it. I have long felt that Marvel films were incredibly stale, but it's more recently reached a point of blatantness that people are very much picking up on it and meming the shallow writing.
Aside from needing to serve as a profit machine, the other aspect that may make it hard for art and novelty to thrive in this setting is the extent of the production team. Generally, its at least hundreds if not thousands of total crew members involved. There's two potential issues I could see with this scale. One is that tasks become divided and so granular that I imagine it can lend itself to tunnel vision and a loss of focus for the big picture. Granted, there are specific roles like directors that are tasked with maintaining that focus, but everyone's involvement and execution is relevant. Secondly, it may also suffer from the common pitfalls that are seen with complex bureaucracies and big corporations. Namely, friction to execution, diffusion of ownership, and having to play a game of telephone to communicate a vision into action, among other obstacles. It's strange to think of the creation of art needing to have Jira tickets.
Overall, the process seems to incentivize approaches that favor the exploitation side of the spectrum of the exploration and exploitation tradeoff. In other words foregoing the potential for greater quality and novelty for predictable cookie-cutter templates, which becomes a greater detriment with repetition causing things to get old and less surprising when many yearn for novelty.
I've had very mixed feelings about the advent of AI art and what that means for humanity and how we perceive value. On one hand, to deny how the proliferation of slop has desensitized us to things that may have once been interesting and how it affects the role and livelihoods of artists in a creative process would be coping. (Though I'd argue as well, is it AI that creates slop? Or is what leads to the feeling of blandness and soullessness more generally a creative process that is overly optimized for conventionality as discussed above?)
On the other hand, I think its opened up doors to entirely new mediums of art, like those who have pioneered hybrid pioneered like 3D NERF painting, or those who have leaned into the strangeness and intricacies of AI like these accounts, straying away from replicating what already exists and turning it into a beast of its own. It is also nice to see where collaborations are very apparent, like where people have animated their paintings with image-to-video. It's absolutely okay if your skills or time fall short in some areas, it still remains expression. We don't discount creatives who work on joint projects together, so I see no reason to do that here either. I recall someone had mentioned to me that some of the very first TV commercials involved someone just standing in front of a camera and reciting a script, basically just replicating what was done for radio commercials and barely making use of the new degrees of freedom for creation. Similarly, I think what will be most novel and enthralling are the works that fully rise to meet the raised ceiling and push against it. With regards to the previous discussion as well, one interesting aspect is how it may allow smaller teams to do more, getting less tangled in the tedious parts and being able to give adequate focus to the big picture of expression. Also, possibly a tad naively optimistic view is that I would hope it can allow for more people to engage, appreciate, and experience art from a hands-on perspective rather than exclusively observation. One thing I do not get so down with is the "democratization of art" dialogue, as this portrays the movement as a virtuous rebellion against the oligarchs of art-making, which is frankly, a bit pretentious. The progression of this technology is an inevitable unstoppable force, and we'll all have to figure out how to ride the waves, though its unfortunate to see when artists by trade, who I think may be reasonably shaken about how a very large portion of their identities and role in the workforce is changing rapidly, are told its unreasonable to be upset and that this technology will allow them to work faster.
So how can one wield noise for creating novelty? I think in part this is easier said than done, and in part, its ingrained in one's nature. Asking people to be random will show you how difficult it is to achieve true randomness. Within population randomness is challenging when you ask people to all choose a random number, and challenging as well if you ask one person to name a sequence of random numbers. But I think there are ways we can consciously choose to search for it. I would say try shit, anywhere and everywhere. Welcome surprises, and lean into them, even if it only interests you, and even if you aren't sure yet if it will interest you. Pursue and dive into passing thoughts. Consider the things you want to try outside of external metrics and expectations. Repurpose mistakes or blemishes, a mistake is only a mistake if thats the context its been placed under. Increase the breadth of your search space. At steps along a creation, try throwing some randomness into it and see how you can riff of that. Benefitting from our knack for recognizing order, one of those things you try is bound to hit the marks of being both rare and interesting.
A big portion of the art I've done nowadays is leaping off of failed ML experiments. This was inspired by a bug in training a model to remove backgrounds, but I had accidentally mixed up the training data's pairs of images and their respective background masks.

Or this was the product of a bug in code for model merging, causing a selection of weights in a network to be randomized, effectively giving the digital brain a lesion and why I've come to call it Lobotomy art.

It's not necessarily wildly skillful, but they did captive my interest for a moment.
I've heard people say that one of the final frontiers for humans is the skill of taste, and I think I'm only just starting to understand that. Having a heuristic to search a massive space and single out interesting, aesthetic things is definitely a skill. And more than ever with AI combined workflows, do we have the capability to play the role of directors, composers, and conductors in executing a vision while still being heavily involved in the piece.
You look at something like AlphaZero, it's ability is very literally searching the space of possible chess moves and how they play out against an opponent, powered by both recognizing what makes a good move and a heuristic for searching efficiently rather than brute-force simulating all possible outcomes. This heuristic is important for quickly trimming down the tree and selecting only the paths that "matter".
Another example I'd mention is if you wanted to set up an algorithm to recreate the works of Shakespeare. The Infinite Monkey theorem says with enough monkeys armed with typewriters and enough time, we would eventually reach this, though possibly not before the heat death of the universe. We could ease this a bit by giving the monkeys special typewriters that corresponded to picking a word rather than an individual character. Then meanwhile an LLM, still guided by random sampling, is much further constrained by grammar and textual knowledge and might complete this goal millions of times faster than the monkeys.
AlphaChess and creating the works of Shakespeare however are tasks where the signal guiding search is relatively trivial. Winning/losing and correct/incorrect offer clear ways to improve, even if the model itself has to learn the intermediate signals of what lead to these outcomes. For more ambiguous notions like beauty or rare bits of novelty, which are susceptible for reward-hacking into slop, that is where we come into play as curators. In essence, I would conclude an approximate description of creativity may be the ability to search for novel, interesting outcomes, especially in unsuspecting areas, guided by a vision and heuristic such that it can be done in reasonable time.
It all comes back to search.
Comments